AI突破算力瓶颈
后摩智能CEO吴强讨论AI算力瓶颈与存算一体;陶哲轩分享AI辅助数学研究经验;15岁量子物理博士投身AI医学;OpenAI计划在ChatGPT中嵌入广告;NeurIPS提出优化大模型解码的新方法;北京快递外卖用车将获专用号牌;AI在电商中的应用;James Cameron批评生成式AI;空中客车因太阳辐射风险订购软件修复;Supabase CEO分享公司成长经历;36氪:军工柔性互连企业入围海底空...
行业新闻
后摩智能创始人兼CEO吴强:端边通用AI算力瓶颈迎来破局点,存算一体将重构产业生态
后摩智能创始人兼CEO吴强在WISE2025商业之王大会上表示,端边侧计算将从以逻辑控制为主转向以AI为主,面临“存储墙”与“功耗墙”的挑战。公司选择了“存算一体”技术路径,推出首款针对端边大模型的芯片M50,以10W功耗提供100-160T算力,支持百亿级参数大模型在端侧运行。公司正基于下一代DRAM PM存算一体芯片,与机器人算法及方案厂商共同推进“最强大脑”式的芯片解决方案。
热门开源项目
NeurIPS 2025 | Language Ranker:从推荐系统的视角反思并优化大模型解码过程
北京大学林宙辰、王奕森团队提出一种新的解码视角——将大模型的解码过程类比为推荐系统中的排序阶段,提出了一种轻量的改进方案。论文指出,现有解码方法缺乏学习能力,存在重复造轮子的问题。通过将大模型的解码过程类比为推荐系统的排序阶段,揭示了现有方法的局限,并据此提出了高效、轻量的改进方案。该模型同时实现了SOTA准确率、低延迟、高吞吐。

学术论文
NeurIPS 2025 | 英伟达发布Nemotron-Flash:以GPU延迟为核心重塑小模型架构
英伟达研究院从真实GPU延迟出发,重构小模型架构。Nemotron-Flash实现了SOTA准确率、低延迟、高吞吐,打败了众多业界小模型。研究表明,小模型之所以不快,是由于深宽比、Attention成本和模型训练后期“提前退场”等因素的影响。该模型已集成进TensorRT-LLM,单H100 GPU吞吐可达41K tokens/second。

技术趋势
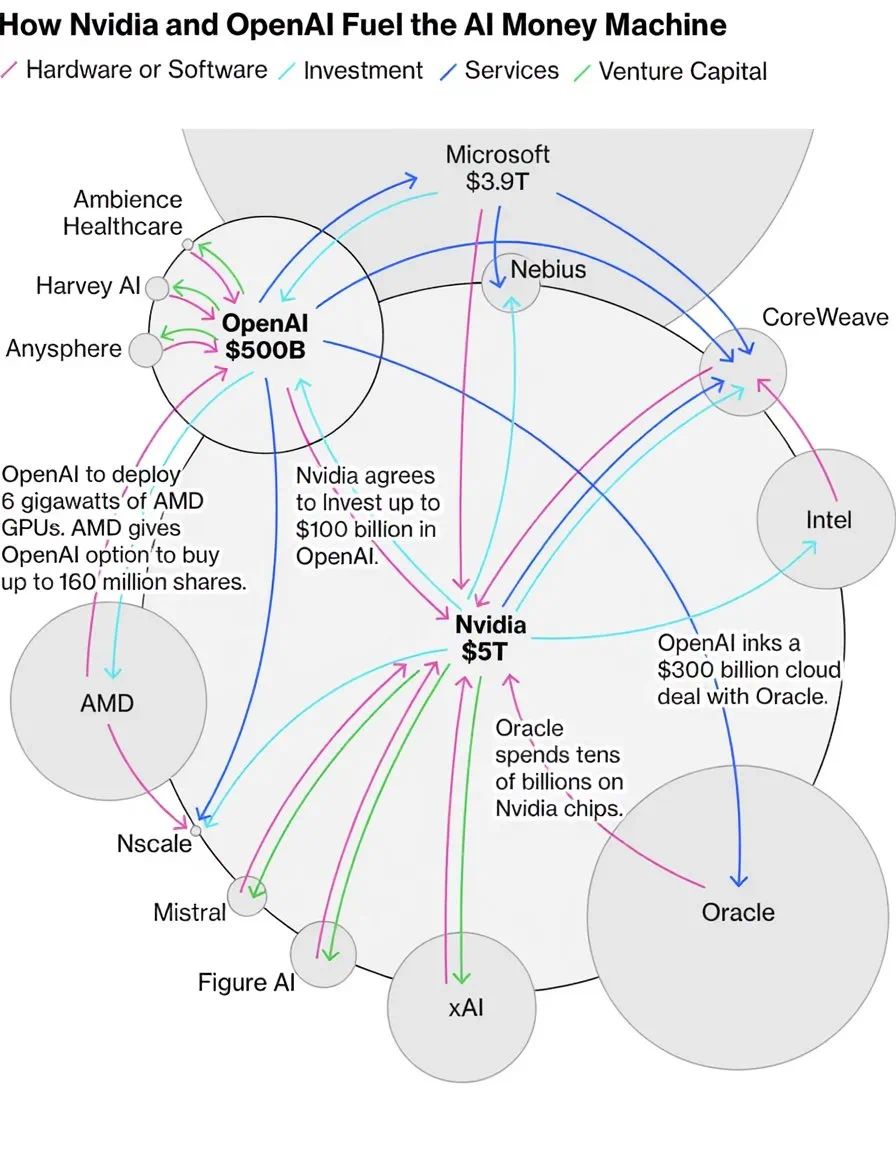
AI驱动的行情:AI终于成了淘金的铲子
AI股票的热潮中,几家科技巨头之间的资金网络推动着AI技术的前进。例如,OpenAI与Oracle签订了巨额合同,Oracle股价暴涨,随后又与英伟达签订了战略合作意向书,英伟达股价再创新高,最终形成了一圈资金在几家科技巨头之间画圈的复杂网络。这种资金循环让AI繁荣在市场层面得到了体现。